Clean Architecture
Descubre Clean Architecture: qué es, cómo funciona y cómo aplicarla en tu desarrollo de software. Exploraremos los conceptos esenciales de esta metodología y su impacto en la construcción de aplicaciones.
¿Qué es una arquitectura o patron de diseño?
Una arquitectura de software es un marco o estructura organizada que define cómo se diseñará, construirá y organizará un sistema de software. Funciona como un plano o un esqueleto que establece las reglas y directrices para crear una aplicación.
En otras palabras menos tecnicas, es como el diseño interno de la aplicación que establece reglas, estándares y patrones de organización para garantizar que el software sea escalable, mantenible y cumpla con los requisitos del proyecto, define cómo se estructuran los componentes, cómo interactúan entre sí y cómo se gestionan los datos. También proporciona una guía para el desarrollo colaborativo y la comprensión del código por parte de otros miembros del equipo.
Arquitectura de Software (Software Architecture): Este se asemeja a los planos generales de una casa. Define la estructura global de la aplicación, incluidas las interacciones de alto nivel entre sus componentes principales. La arquitectura de software establece las bases y los principios fundamentales que guían cómo se construirá y organizará todo el sistema.
Diseño de Software (Software Design): Esto se asemeja a los detalles específicos de una casa, como la ubicación de la cocina, la disposición de las habitaciones y la elección de materiales y colores. En el contexto del desarrollo de software, el diseño de software se refiere a cómo se implementan los componentes individuales, cómo se organizan las clases y funciones, y cómo se resuelven los problemas específicos dentro de cada módulo.
MVC
Cuando comenzamos en el desarrollo de software y exploramos el mundo del backend, MVC (Modelo-Vista-Controlador) es uno de los primeros patrones de arquitectura que encontramos. Si bien es adecuado para aplicaciones sencillas o CRUDs, se centra principalmente en la manipulación de datos y puede volverse complejo a medida que nuestras aplicaciones crecen en tamaño y complejidad. En este punto, es donde Clean Architecture entra en juego.¿Como funciona?
MVC se basa en la separación de la lógica de presentación, la lógica de la aplicación y los datos. Es una elección sólida para aplicaciones más simples, pero cuando agregamos características avanzadas o integramos servicios externos, como OAuth de Google o Facebook, nuestro código puede volverse confuso y difícil de mantener. Cambiar una característica puede afectar múltiples partes del código, lo que lo hace poco escalable.
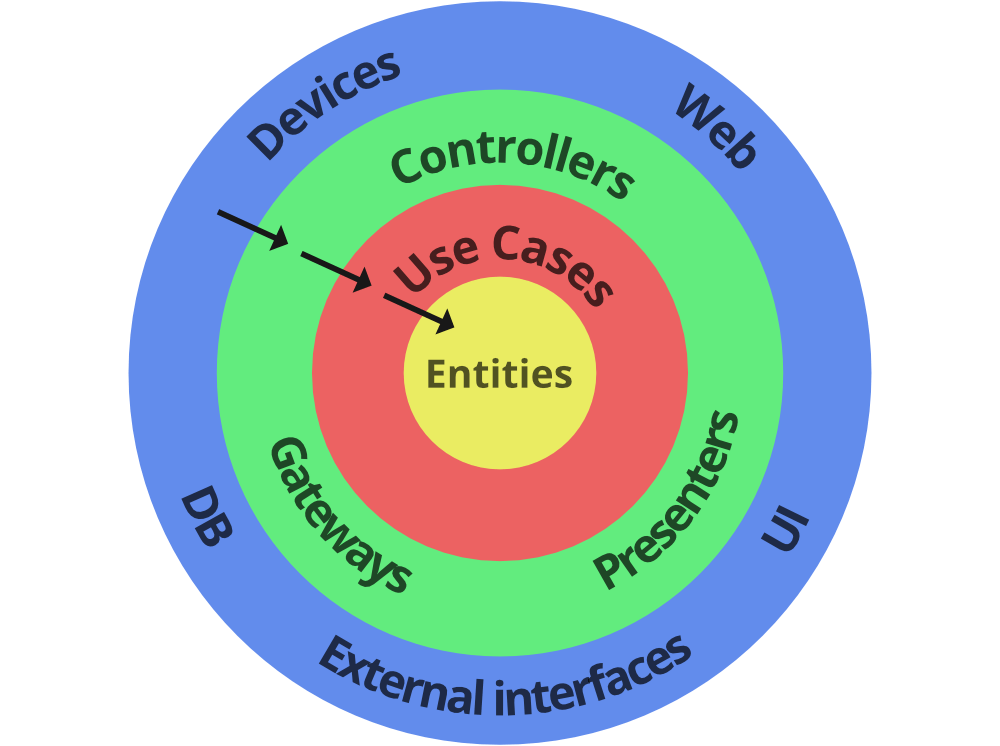
Clean Architecture ofrece una solución. En lugar de reemplazar MVC, complementa este patrón con una estructura de capas que enfatiza la independencia y la organización.
Coloca el núcleo de la aplicación, donde residen las reglas de negocio, en el centro y mantiene las capas externas, como la interfaz de usuario y las bases de datos, en los bordes. Esto facilita la independencia de las capas y la prueba de la lógica de negocio sin preocuparse por los detalles de implementación.
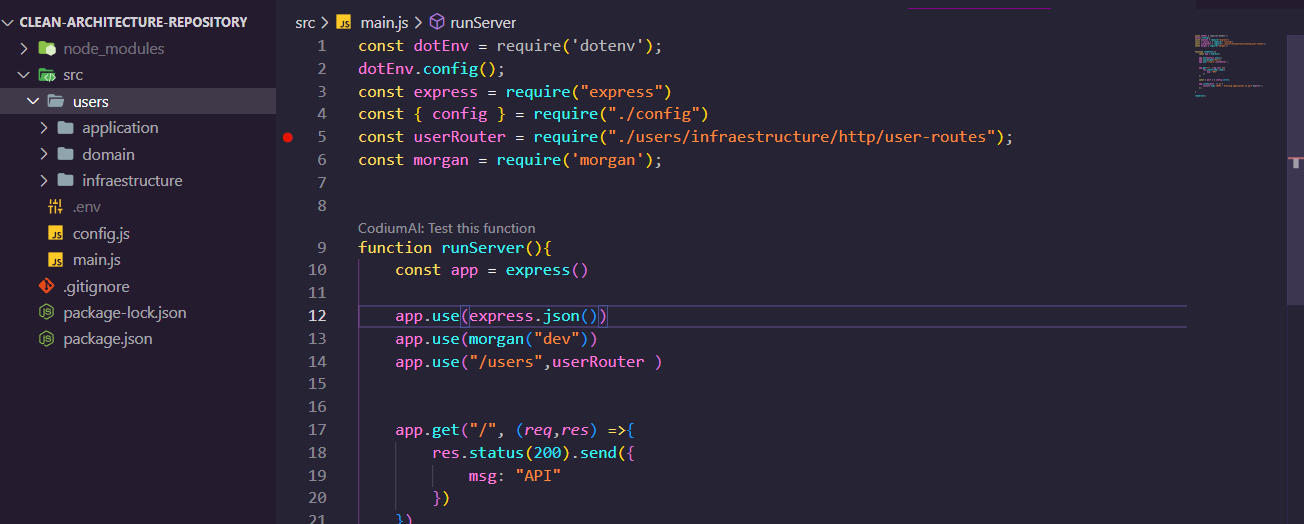
Esta seria una representación visual de lo que estabamos hablando, como se ve el MVC en un backend sencillo de express.js
Clean Architecture
Clean Architecture es un enfoque de diseño de software que se centra en la creación de sistemas robustos, escalables y mantenibles. A diferencia de otros patrones de arquitectura que pueden volverse complejos a medida que los proyectos crecen, Clean Architecture propone una estructura modular que separa las preocupaciones y fomenta la independencia entre las distintas partes de una aplicación. Veamos en detalle las capas clave de Clean Architecture:
Capa de Dominio
Vayamos adentrandonos a este maravilloso mundo de Clean Architecture 🤓🚀
En el corazón de Clean Architecture se encuentra la capa de Dominio. Esta capa representa las reglas de negocio y define las entidades centrales de la aplicación, en palabras mas simples, es la forma en que nosotros definimos que hara nuestra aplicación pero sin preocuparse de “como” lo hará, ya que esa no es su reponsabilidad y es donde entra una regla de dependencia.
En esta capa definimos que tipos de datos tendra el Usuario, que tipo de version tendra nuestra aplicación y framework, la configuración del sistema y más.
Aqui podemos tener como se configurara o conectará a la DB o el entorno de Node js.
- Entidades: Definen la estructura y comportamiento de los elementos centrales de la aplicación.
- Reglas de Negocio: Especifican cómo se deben realizar las operaciones y validaciones en el sistema.
- Configuración: Puede incluir datos de configuración que afectan el comportamiento de la aplicación, como URLs de API o claves de acceso.
Capa de Casos de Uso (Use Cases)/ Aplicación
La capa de Casos de Uso contiene la lógica de negocio de la aplicación. Aquí se definen las interacciones y operaciones que los usuarios pueden realizar en el sistema.Los casos de uso actúan como intermediarios entre la capa de Dominio y la capa de Infraestructura, asegurando que las reglas de negocio se apliquen correctamente sin preocuparse por los detalles de la implementación.
En el caso de uso (use case), los archivos o clases esperan una inyección de interfaces que, en otras palabras, son los datos de infraestructura, como la base de datos o la configuración en general.
-
Lógica de Negocio: Implementa las operaciones específicas que la aplicación debe realizar, como crear usuarios, procesar pedidos o calcular estadísticas.
-
Interacción con Entidades: Los casos de uso utilizan las entidades definidas en la capa de Dominio para realizar operaciones.
-
Inyección de Dependencias: Se utilizan interfaces para interactuar con la capa de Infraestructura, permitiendo la flexibilidad y la sustituibilidad de componentes externos.
Capa de Interfaz (Interfaces) y Patrón Repository
La capa de Interfaz proporciona un conjunto de interfaces que actúan como contratos entre la capa de Casos de Uso y la capa de Infraestructura. Estas interfaces definen cómo los casos de uso pueden acceder a servicios externos, como bases de datos, servicios web o sistemas de autenticación. La capa de Interfaz asegura que los casos de uso no dependan directamente de la infraestructura, lo que facilita la adaptabilidad y la prueba unitaria.
Interfaces de Base de Datos: Definen métodos para interactuar con la base de datos, como guardar o recuperar datos.
Interfaces de Autenticación: Especifican cómo autenticar usuarios y generar tokens de seguridad.
Interfaces de Servicios Externos: Permiten la integración con servicios externos, como APIs de terceros.
El patrón Repository se utiliza en la capa de Interfaz para definir interfaces que actúan como contratos entre la capa de Negocio (o Casos de Uso) y la capa de Repositorio. Estas interfaces de Repositorio definen cómo la lógica de negocio puede acceder y manipular datos almacenados, como bases de datos, sin depender directamente de la infraestructura de almacenamiento subyacente. El patrón Repository asegura un desacoplamiento eficiente entre la lógica de negocio y la tecnología de almacenamiento, lo que facilita la adaptabilidad y la prueba unitaria.
Interfaces de Repositorio: Estas interfaces definen los métodos y operaciones necesarios para acceder a los datos almacenados, como métodos para guardar, recuperar, actualizar o eliminar registros.
Implementaciones de Repositorio: En la capa de Infraestructura de Datos, se proporcionan implementaciones concretas de las interfaces de repositorio que se conectan a la fuente de datos real, como una base de datos SQL o un servicio web.
El patrón Repository permite a la lógica de negocio trabajar con abstracciones de datos en lugar de interactuar directamente con la infraestructura de almacenamiento, lo que facilita el intercambio de la fuente de datos sin afectar a la lógica de negocio principal. Esto promueve la modularidad, la mantenibilidad y la escalabilidad de la aplicación.
Capa de Infraestructura
La capa de Infraestructura se encarga de la implementación concreta de los servicios externos y recursos técnicos, como bases de datos, servidores web, sistemas de archivos, entre otros. Aquí es donde se conectan los puntos entre la aplicación y el mundo exterior. Clean Architecture fomenta que esta capa sea reemplazable y que los cambios en la infraestructura no afecten la lógica de negocio.
-
Implementación de Bases de Datos: En esta capa, se gestionan las operaciones de lectura y escritura en la base de datos. Es posible utilizar diferentes motores de bases de datos sin afectar la lógica de negocio.
-
Implementación de Servidores Web: Aquí se define cómo la aplicación se expone al mundo exterior a través de un servidor web. Ejemplos de servidores web incluyen Express.js, Nest.js, Django, entre otros.
-
Conexiones con Servicios Externos: Esta capa se encarga de integrar servicios externos, como APIs de terceros, autenticación OAuth y otros sistemas.
Esta es una forma de poner en practica estas capas de Clean Architecture